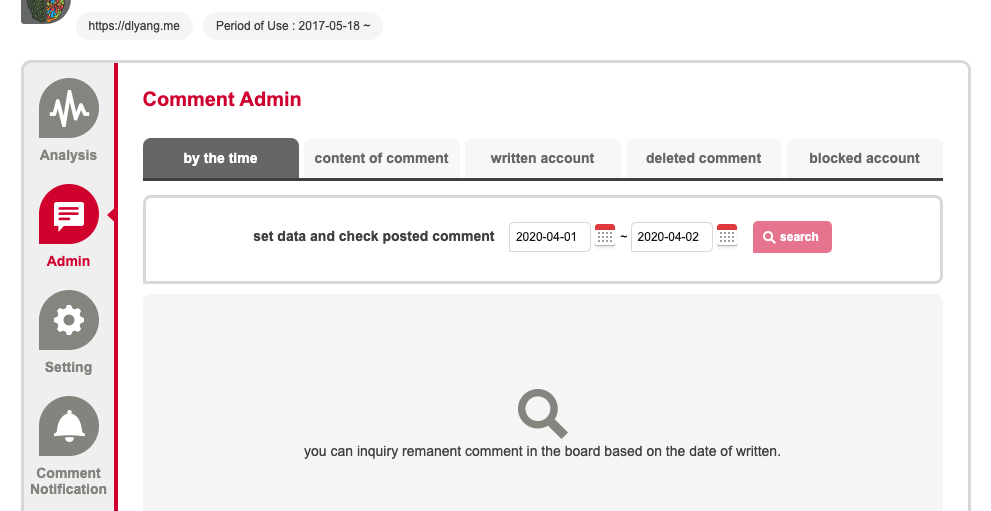
defhandle_starttag(self, tag, attrs): # State machine if tag == 'tr'andlen(attrs) >= 6: # New comment # print(attrs) self.d_buf = self.dict_template.copy() for f in attrs: # print(f) if f[0] in self.field_map.keys(): self.d_buf[self.field_map[f[0]]] = f[1] # print(self.d_buf)
elif tag == 'td'and'table-content-regdate table-padding'in [ at[1] for at in attrs ]: self.is_date = True elif tag == 'td'and'table-content-title table-padding'in [ at[1] for at in attrs ]: self.is_title = True
elif tag == 'a'and self.is_title: link = attrs[0][1] thread_id = link.split('/')[3] self.d_buf['thread_id'] = thread_id self.d_buf['post_link'] = link.split('#')[0]
elif tag == 'p'and ('class', 'content-text') in attrs: self.is_content = True
elif tag == 'br': # second part of date self.is_date = True
defhandle_data(self, data): # the date must be in 'YYYY-MM-DD HH:MM:SS' 24-hour format. if self.is_date: # print(data) if'/'in data: date_list = data.split('/') self.d_buf['comment_date'] = '-'.join(date_list[::-1]) if'M'in data: # AM or PM. "PM 12:09 --> 12:09:00" time_list = data.split(' ') hms_list = time_list[1].split(':') hms_list = [int(x) for x in hms_list] if time_list[0] == 'PM': if hms_list[0] != 12: hms_list[0] += 12 self.d_buf['comment_date'] += ' {0:02d}:{1:02d}:33'.format( hms_list[0], hms_list[1]) self.is_date = False
defhtml_to_json(self): """Required fields: - Post title - Post link - thread identifier (post url without the site link) - post_date - comment status: "open" by default - Each comment: - id: int string - author - email (can be empty) - author url (can be empty) - author IP (make up one) - date_gmt: comment timestamp - content - approved: 1 by default - parent: the parent comment_id (can be empty) """ f_list = self.get_filename_list_by_ext('./html_tables/', 'html') print(f_list) # return # SAFETY
for ftab in f_list: my_html_parser = LiveReTableParser() withopen(ftab, 'r', encoding='utf-8') as f_tab: all_txt = '' for l in f_tab: all_txt += l my_html_parser.feed(all_txt) f_tab.close()
defget_filename_list_by_ext(self, file_path, f_extension): # This one only gets the current log. print(file_path) f_list = [] for root, dirs, files in os.walk(file_path): for file in files: if file.endswith(f_extension): f_list.append(os.path.join(root, file)) return f_list
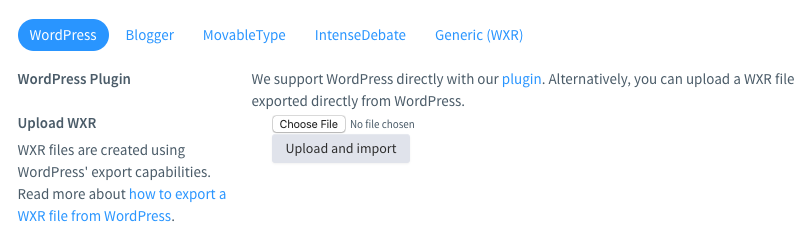
defjson_to_disqus_xml(self): print("Convert Json to XML pipeline.") if Path(json_fp).exists(): withopen(json_fp, encoding='utf-8') as jf: cmt_list = json.load(jf) else: print( 'json file not exists. Please run the \'html to json\' pipeline first. ' ) header_str = '''<?xml version="1.0" encoding="UTF-8"?> <rss version="2.0" xmlns:content="http://purl.org/rss/1.0/modules/content/" xmlns:dsq="http://www.disqus.com/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:wp="http://wordpress.org/export/1.0/" > <channel> ''' ending_str = ''' </channel> </rss> ''' formatted_xml_str = header_str for cmt in cmt_list: cmt_element = ''' <item> <title>{0}</title> <link>{1}</link> <content:encoded><![CDATA[{2}]]></content:encoded> <dsq:thread_identifier>{3}</dsq:thread_identifier> <wp:comment_status>open</wp:comment_status> <wp:comment> <wp:comment_id>{4}</wp:comment_id> <wp:comment_author>{5}</wp:comment_author> <wp:comment_author_email></wp:comment_author_email> <wp:comment_author_url></wp:comment_author_url> <wp:comment_author_IP>127.0.0.2</wp:comment_author_IP> <wp:comment_date_gmt>{6}</wp:comment_date_gmt> <wp:comment_content><![CDATA[{2}]]></wp:comment_content> <wp:comment_approved>1</wp:comment_approved> <wp:comment_parent></wp:comment_parent> </wp:comment> </item>'''.format(cmt['post_title'], cmt['post_link'], cmt['comment_content'], cmt['thread_id'], cmt['comment_id'], cmt['comment_author'], cmt['comment_date']) formatted_xml_str += cmt_element formatted_xml_str += ending_str
# Write to file withopen(self.disqus_xml_fp, 'w', encoding='utf-8') as f_xml: f_xml.writelines(formatted_xml_str)
print("Convertion done --> disqus_import.xml")
if __name__ == "__main__": my_cm = CommentMigrator() func_switch = 1 if func_switch == 1: my_cm.html_to_json() elif func_switch == 2: my_cm.json_to_disqus_xml()
 微信
微信